




Shard: “Shard” means “a small part of a whole“. Hence Sharding means dividing a larger part into smaller parts. These shards are not only smaller but also faster and hence easily manageable.
Producer: An Amazon Kinesis Data Streams producer is an application that puts user data records into a Kinesis data stream (also called data ingestion). The Kinesis Producer Library (KPL) simplifies producer application development, allowing developers to achieve high write throughput to a Kinesis data stream.
Consumer: An Amazon Kinesis Data Streams producer is an application that puts user data records into a Kinesis data stream (also called data ingestion). The Kinesis Producer Library (KPL) simplifies producer application development, allowing developers to achieve high write throughput to a Kinesis data stream.
the final goal we have is that we have very big data what is the use of this data one of the use of this data is to analyse.
so first we have to collect the data.
KDS(Kubernetes data stream) help in managing the data.
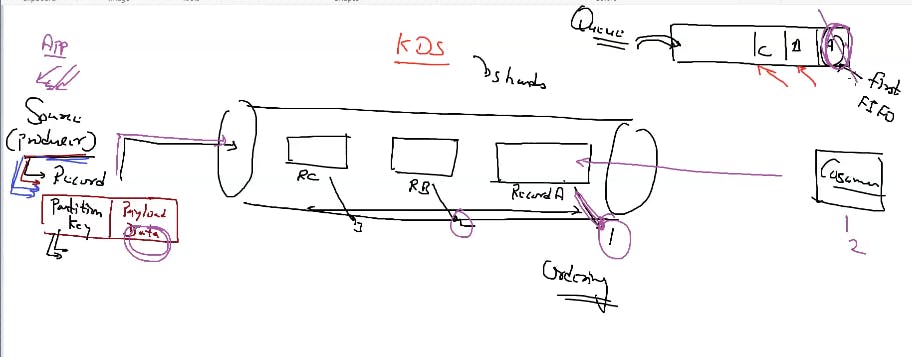
as we already know partition key which decides that in which shard it should go. data go in the form of records in sequence and consumers consume the data on the basis of first in first out. It first consume it destroys it then use the next data. The life of the data is the life of the queue.
How to ingest the data in the shard
command to create the datastream through aws cli:
aws kinesis create-stream --stream-name mayWeblogStream --shard-count 3 --region ap-south-1
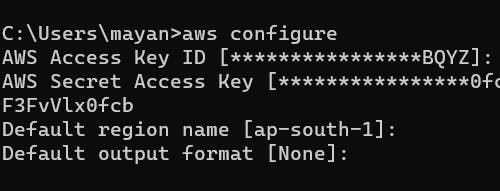
first configure aws cli through IAM user (access and secret key ) then create the data stream

don't learn the commands use help it provide required information for making full command
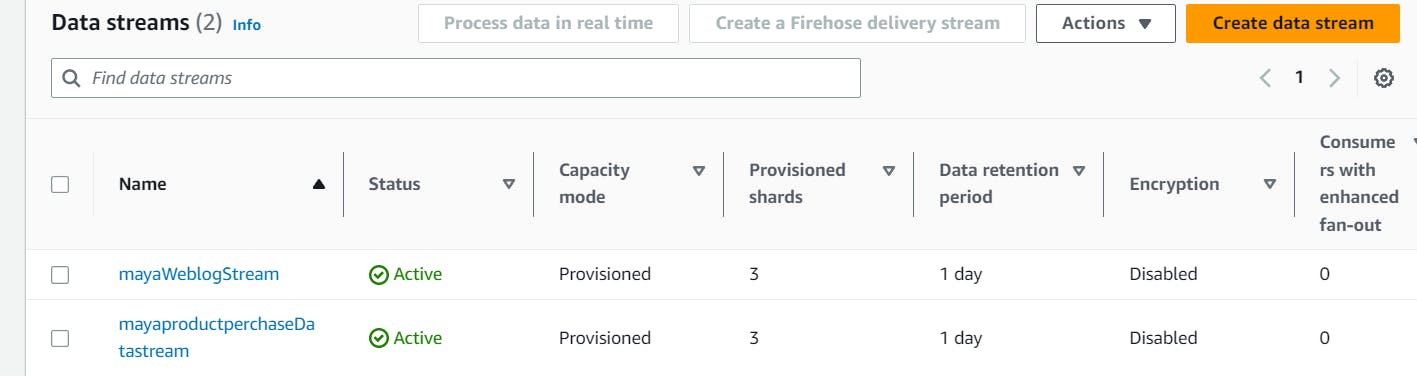
we have one data stream
we have a app running in nodejs in which we install the libraries let say java , javascipt given in aws and put this in code by the the developer of app . these library had a capability to capture the data and send it to KDS(kinesis data stream
there are two types of library Multiple ways to write data in Kinesis:
- SDK (software developement kit)[native]
2)KPL (kinesis producer library)[CLI through command line]
This is one of the way to collect the data
S3 services: Amazon Simple Storage Service (Amazon S3) is an object storage service offering industry-leading scalability, data availability, security, and performance. Customers of all sizes and industries can store and protect any amount of data for virtually any usecase, such as data lakes, cloud-native applications, and mobile apps. With cost-effective storage classes and easy-to-use management features, you can optimize costs, organize data, and configure fine-tuned access controls to meet specific business, organizational, and compliance requirements.
Multiple ways to write data in Kinesis:
1.. AWS SDK : The AWS SDK for JavaScript simplifies use of AWS Services by providing a set of libraries that are consistent and familiar for JavaScript developers. It provides support for API lifecycle consideration such as credential management, retries, data marshaling, serialization, and deserialization. The AWS SDK for JavaScript also supports higher level abstractions for simplified development.
Kinesis Producer Library (KPL): An Amazon Kinesis Data Streams producer is an application that puts user data records intoa Kinesis data stream (also called data ingestion). The Kinesis Producer Library (KPL) simplifies producer application development, allowing developers to achieve high write throughput to a Kinesis data stream.
Kinesis Agent: Kinesis Agent is a stand-alone Java software application that offers an easy way to collect and send data to Kinesis Data Streams. The agent continuously monitors a set of files and sends new data to your stream. The agent handles file rotation, checkpointing, and retry upon failures. it delivers all of your data in a reliable, timely, and simple manner. It also emits Amazon CloudWatch metrics to help you better monitor and troubleshoot the streaming process.
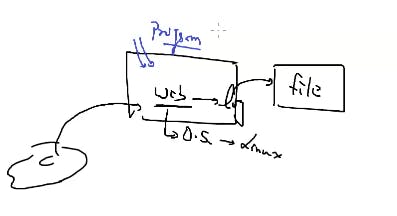
client running a webserver runnning on an os in which a software program is installed which keep on monitoring the file of log on the last as logs are in the tail of program and when any new log or new record found send it to kds(kinesis data stream) This is known as kinesis agent. It is written in java.
Amazon API Gateway: It is a fully managed service that makes it easy for developers to create, publish, maintain, monitor, and secure APIs at any scale. APIs act as the "front door" for applications to access data, business logic, or functionality from your backend services. Using API Gateway, you can create RESTful APIs and WebSocket APIs that enable real-time two-way communication applications. API Gateway supports containerized and serverless workloads, as well as web applications
if we want to ingest data with the help of kinesis agent
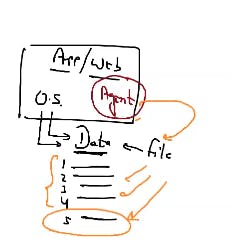
here we install agent program in the os which keep on monitoring whenever new recordd came capture it and send it to kds
lets do demo for
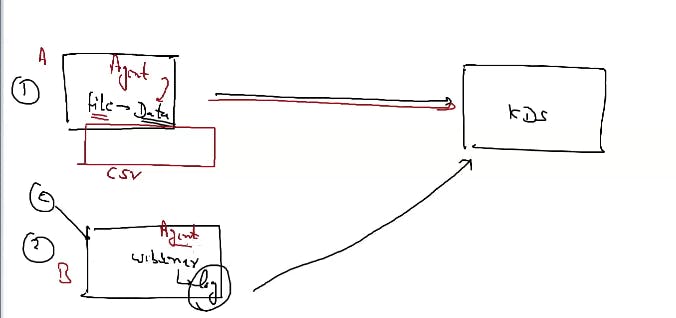
in A we already have a file of data of customer let say in .csv format capture by the agent and send it to kds
in B client is hitting webserver and when new log created agent capture it and send it to kds
create the instance:
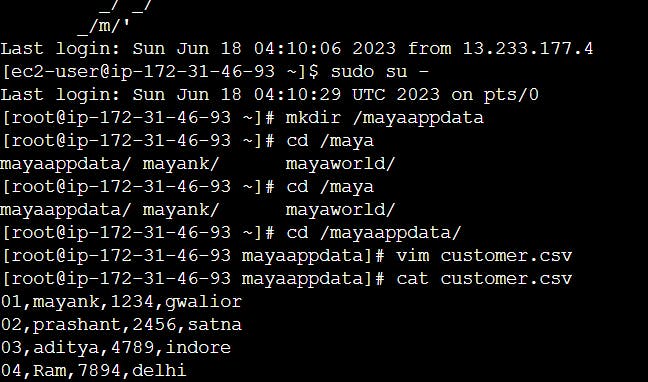
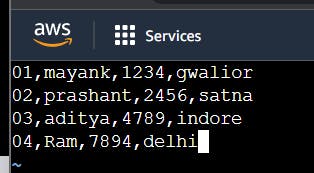
create the folder with any name as mayaappdata and put the data in file named as customer.csv as we don't have to data so make it.
so how to install the agent and how agent do monitor this folder
command : yum install aws-kinesis-agent
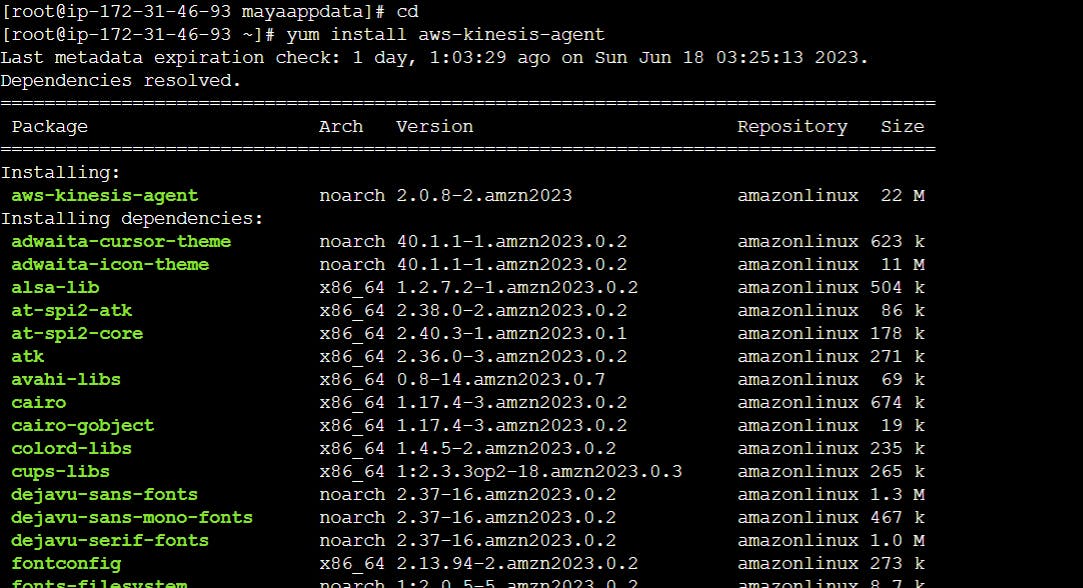
this program help in capture data and send it to kinesis
read about the agent: https://docs.aws.amazon.com/streams/latest/dev/writing-with-agents.html
we have to tell the agent that which file he have to monitor and where to send the data
for this we have to go the configeration file
use : rpm -q -l aws-kinesis-agent
where /etc/aws-kinesis/agent.json
in this file we tell the agent that which file to be monitor
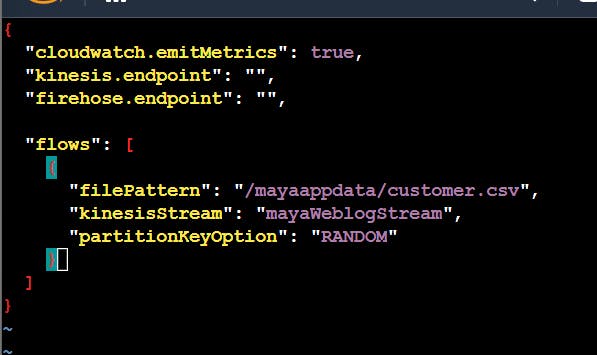
in file pattern we have to tell the path of file which is to be monitored and in kinesiStream we have to tell the data stream to which it is transferred .
kinesis endpoint we don't tell this part as already it is running in aws otherwise we have to tell the url for this.
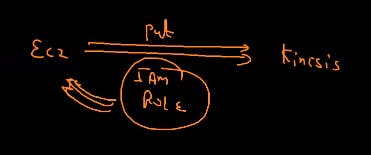
since ec2 is connecting to kinesis for capturing the data stream so we have to give the IAM role for this .
since we are using aws thats why we have to define the role otherwise we don't have to define the role instead we have to tell teh access and secret key and also we have to tell the kinesis.endpoint that is url.
for example if have to send my desktop items to kinesis which is out of aws world so we have to tell the credentials .
so lets create role
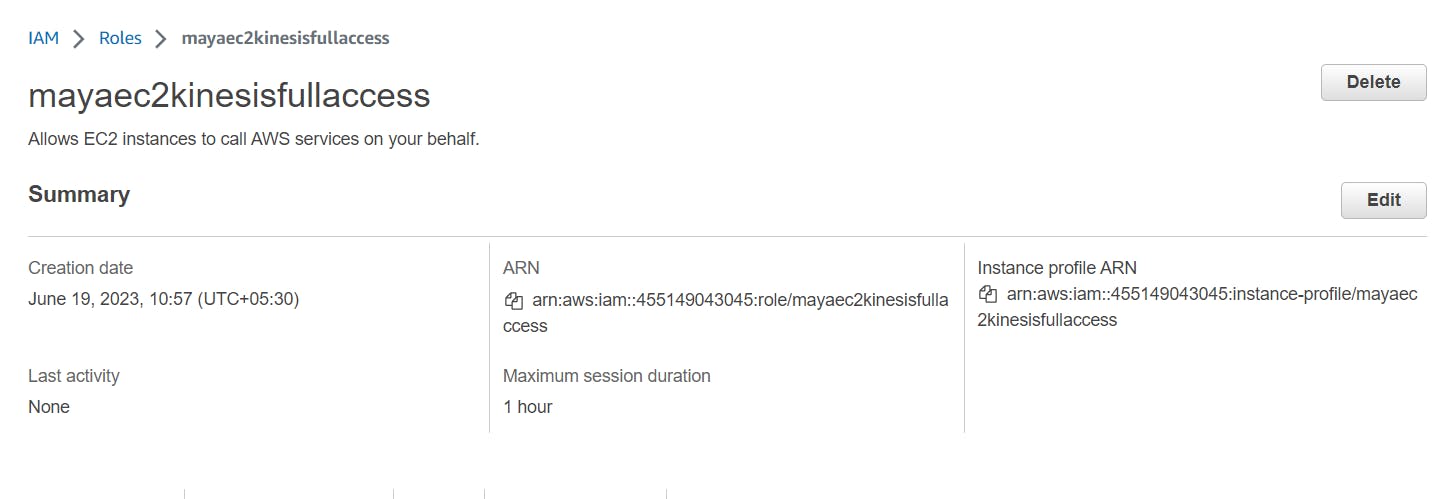
then attach this role to the instance running with agent
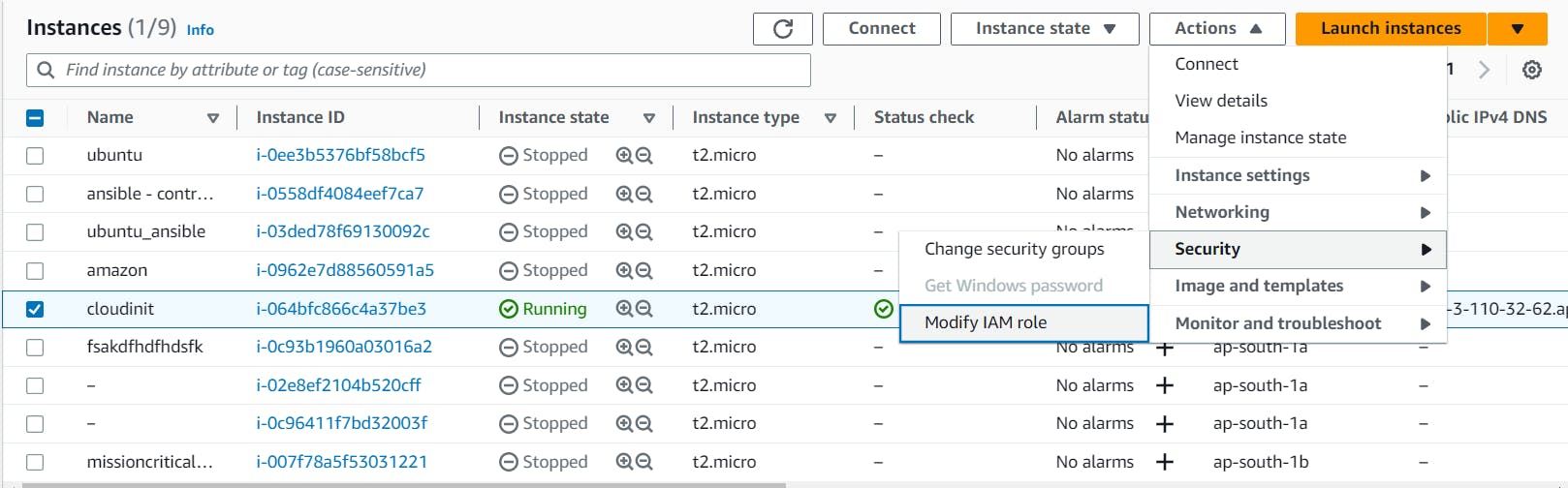
modify the IAM role
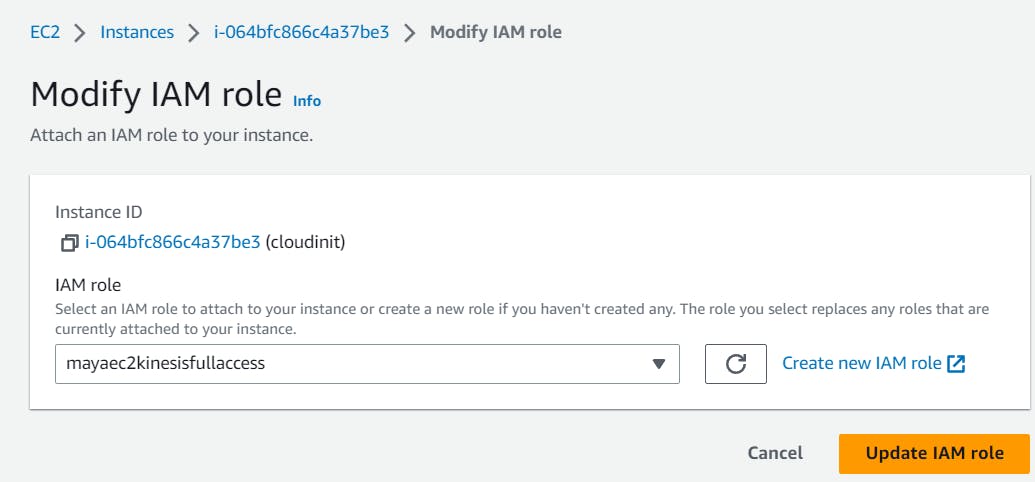
now ec2 have the power to put the data in kinesis
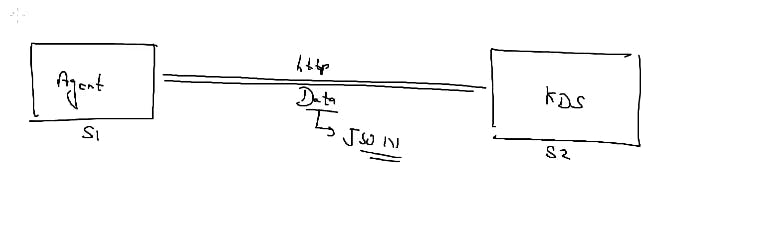
when one service want to share data to another service they are using http protocol and data that is send in the form of json format. but right now i have a data is in the form of .csv format so we have to convert the data in json which is done by our agent
go on this : https://docs.aws.amazon.com/streams/latest/dev/writing-with-agents.html

click on use the agent to pre process data
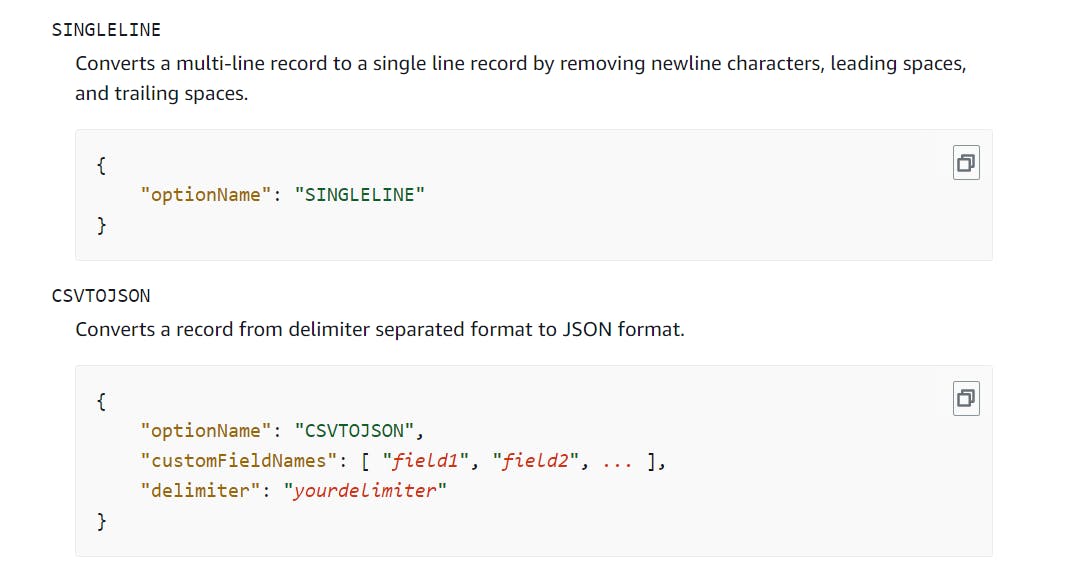
see we have csv to json
since these format come on dataProcessingOptions then we have to add this our configeration file of agent
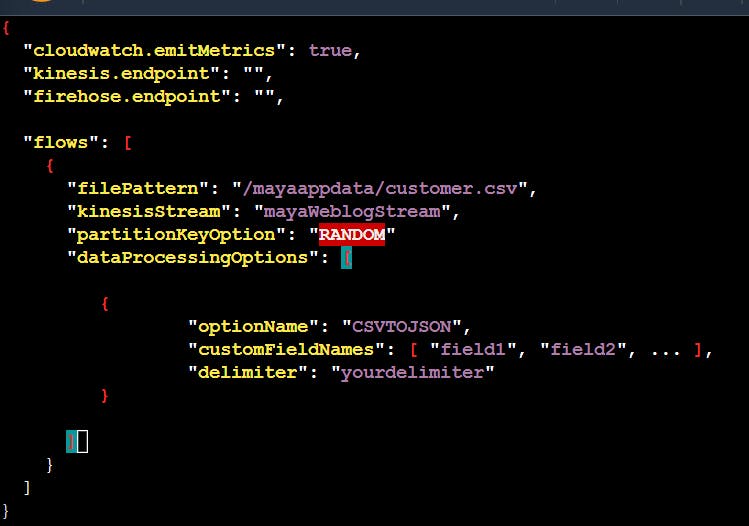
second thing we have to tell that my data is separated with whom that is comma which is here called as delimeter so in delimeter column we have to tell that it is separated by " , "

data coming here is totally a raw data mean their is no row name column name
so before send data

it means we have 4 records in kds
also we know that first field is customer id, second field is of customer name, third field is of mobile number, 4th field is of address so we have to tell this to configeration file of agent under customerField name these are the meta data that we have to tell the agent .
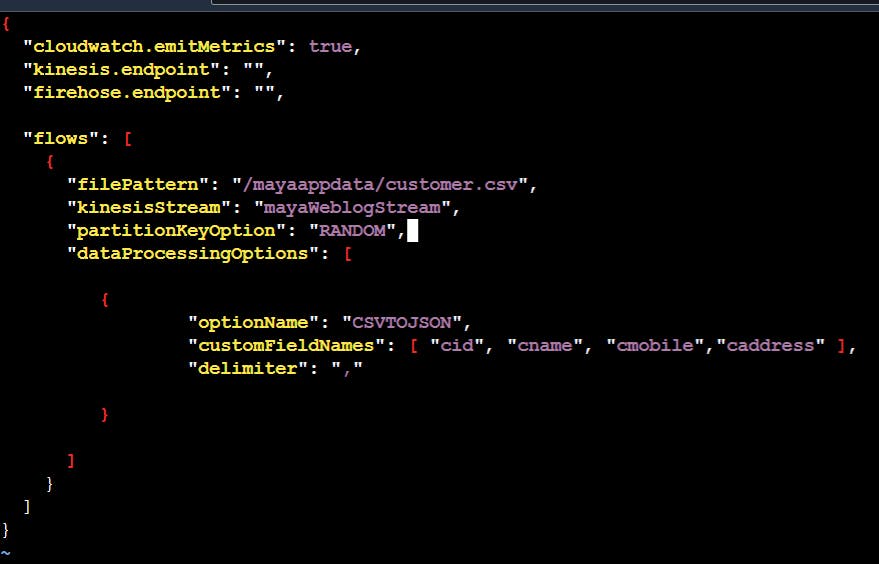
so this is our final configeration file of agent
now we have to start the service of agent
command to start the service: service aws-kinesis-agent start
to check the whether agent start the service or not : service aws-kinesis-agent status
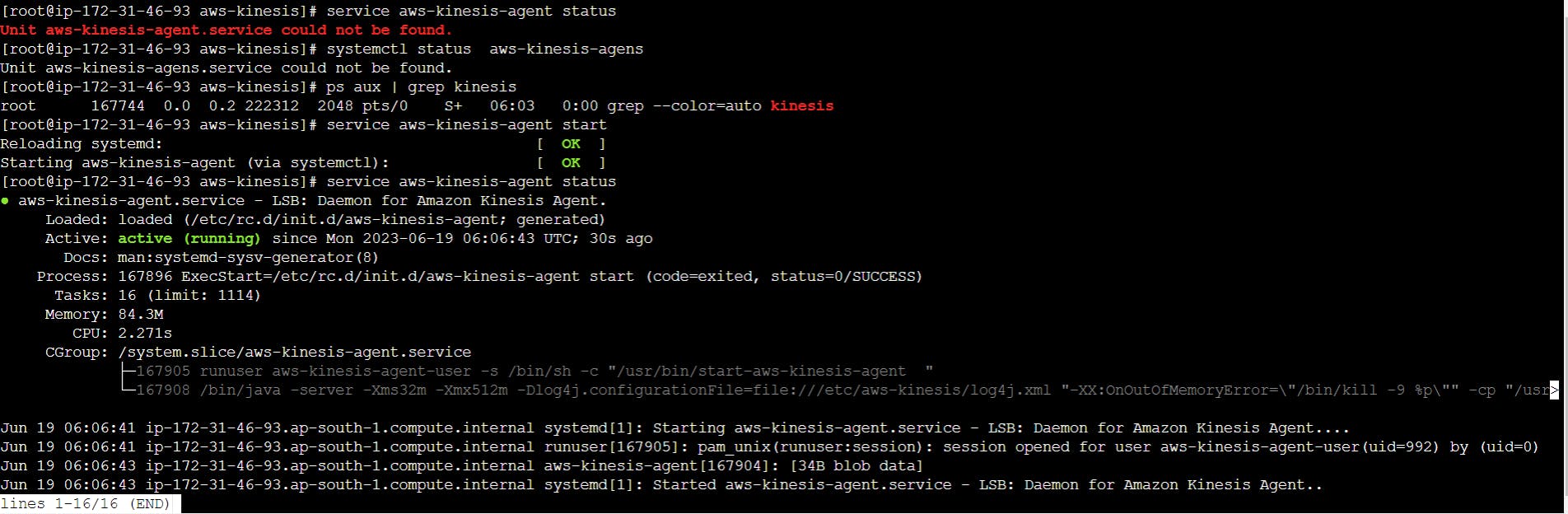
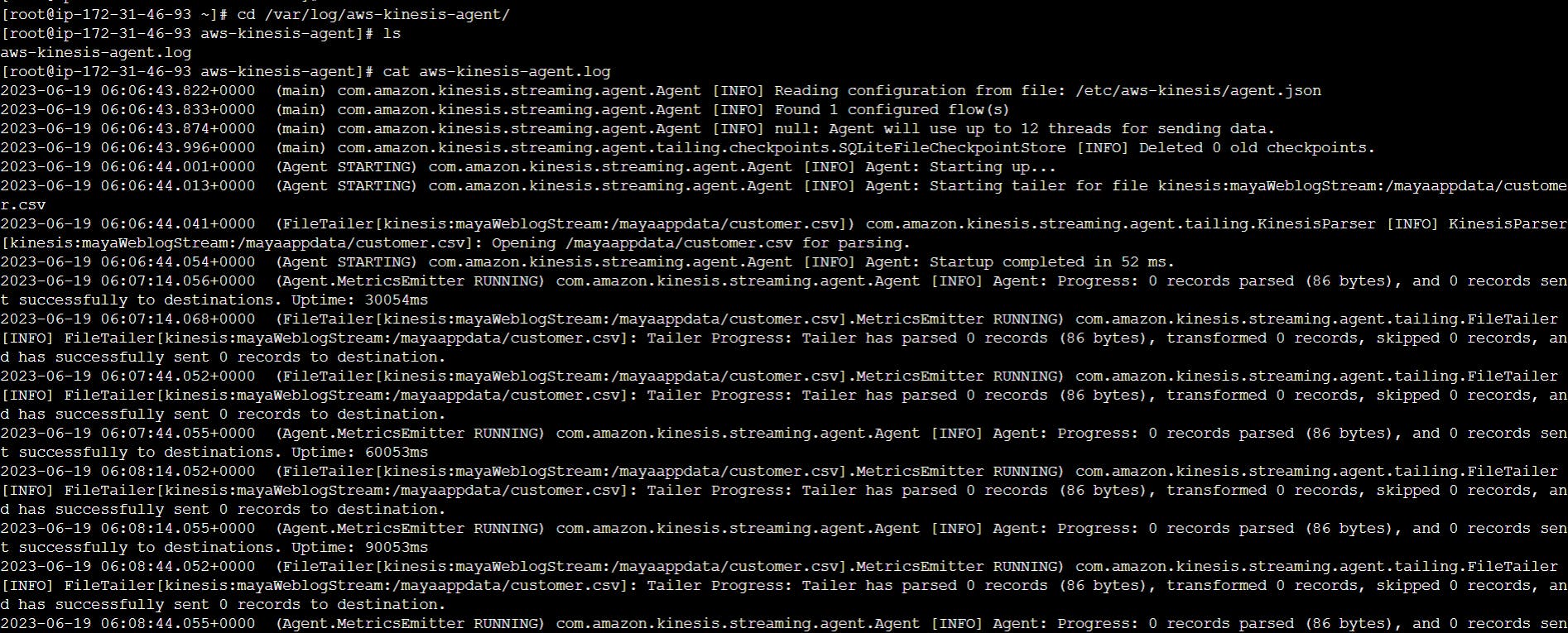
any error causes check the logs created by the agent
logs store in the file : /var/log/aws-kinesis-agent/
what agent is doing keep on monitoring the file
and if you check the kinesis data stream their is not data came as behavior of agent is looking the tail of the file last of the file
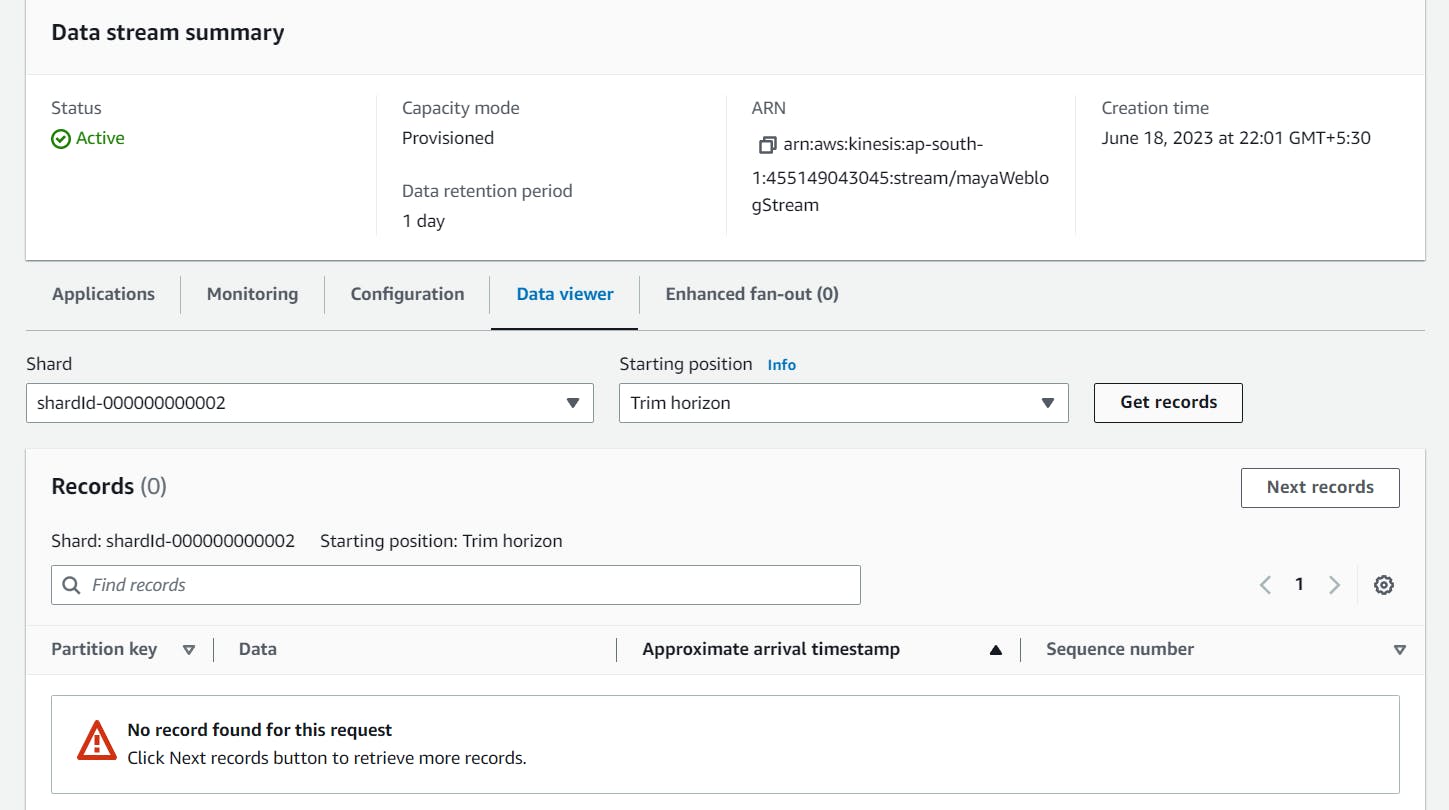
so as soon as we add new record to the file agent will send the data to kinesis data stream
lets add new record

Hope you guy enjoy the blog and learnt a lot .
Want to connect with me
My Contact Info:
📩Email:- mayank07082001@gmail.com
LinkedIn:-linkedin.com/in/mayank-sharma-devops